Easy Object Storage with InfiniBox

An object is a thing observed, something that is tangible and within the grasp of the senses. And for those of us living in the storage world, an object is anything that can be stored and retrieved later. Any digital artifact is an object - an X-ray image, a cat photo, an MP3 audio file, a payslip, a DNA sequence, or LiDAR data from your self-driving car.
More and more often we’re finding Infinibox deployed behind 3rd party object storage solutions. While InfiniBox doesn’t natively implement object protocols today, our customers want to take advantage of the InfiniBox’s reliability, performance, and economics for their object storage environments.

Fig.1: Sample artifacts which may reside on object storage
One interesting example of an S3 implementation is MinIO - an open-source object storage server targeting high performance and AI use cases. It is distributed under the Apache License v2.0. MinIO supports the Amazon S3 protocol and supports objects up to 5TB. There is a long list of MinIO-based community projects at https://github.com/minio/awesome-minio.
A particularly interesting MinIO capability is the NAS gateway. In this mode, MinIO software can run in front of a regular NFS file system and expose its contents via the S3 protocol. This is especially useful with the InfiniBox’s scalable NAS capability, which supports file systems with billions of files.
MinIO NAS gateway can be deployed in minutes, using either a Docker container or running as a binary on a virtual machine/physical server. With such a setup, every object uploaded via the S3 protocol is stored as a file in the underlying InfiniBox NFS file system and is accessible via NFS and S3 protocols.
Let’s demonstrate how easy it is to set up a basic S3-compatible environment using InfiniBox storage and MinIO.
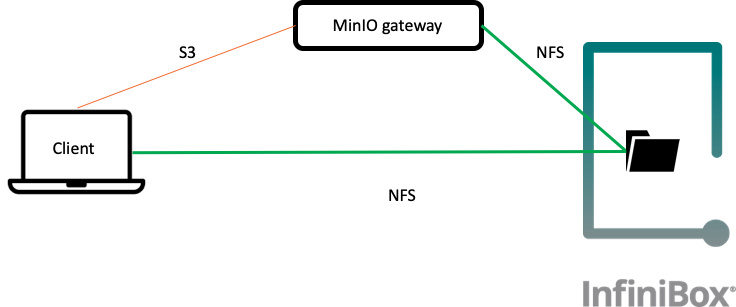
Fig.2 - Test environment demonstrating dual-protocol (S3 and NFS) capabilities
We’ll start with the creation of a 100TiB file system which will be used for MinIO storage. For this example, I’ll use InfiniBox’s InfiniShell command-line interface. The same operations can be performed using the InfiniBox GUI, REST API or Python SDK interfaces. We’ll enable InfiniBox compression for the stored data to provide better capacity utilization:
> fs.create name=minio01 size=100TiB pool=s3_demo thin=yes compression=yes Filesystem "minio01" created > fs.export.create fs=minio01 export_path=/minio01 Export "/minio01" created
As a next step, we’re going to mount this newly created file system on a MinIO gateway host, and download and launch the latest MinIO binary:
[miniogw ~]$ mkdir /mnt/minio01
[miniogw ~]$ mount -o hard,intr,rsize=262144,wsize=262144 \
172.31.32.28:/minio01 /mnt/minio01
[miniogw ~]$ wget https://dl.min.io/server/minio/release/linux-amd64/minio
[miniogw ~]$ chmod +x minio
[miniogw ~]$ export MINIO_ACCESS_KEY=<preferred access key>
[miniogw ~]$ export MINIO_SECRET_KEY=<preferred secret key>
[miniogw ~]$ ./minio gateway nas /mnt/minio01This is all that is required to deploy 100TiB of S3 capacity in your environment using MinIO and InfiniBox. If more capacity is required, just resize the InfiniBox filesystem - no interaction is required with MinIO or any other layers of the solution.
Running MinIO gateway in front of InfiniBox NFS allows dual-protocol access, sharing data between S3 and NFS clients. We’ll use s3cmd for access via the S3 protocol. Start from creating a new S3 bucket and uploading a single object into this bucket:
$ ./s3cmd mb s3://ibox-bucket Bucket 's3://ibox-bucket/' created $ ./s3cmd put testsuite.tar.gz s3://ibox-bucket upload: 'testsuite.tar.gz' -> 's3://ibox-bucket/testsuite.tar.gz' [1 of 1]
Now, this object is accessible over NFS as a file while the bucket becomes a folder:
$ ls -l /mnt/minio01/ibox-bucket total 320 -rw-r--r-- 1 root root 286725 Nov 7 01:25 testsuite.tar.gz
It is also possible to create a file using NFS and access it later using S3 protocol:
$ echo "Is it an object or a file?" > /mnt/minio01/ibox-bucket/filobj $ ./s3cmd get s3://ibox-bucket/filobj && cat filobj download: 's3://ibox-bucket/filobj' -> './filobj' [1 of 1] Is it an object or a file?
All InfiniBox functionality, including compression, replication, and space-efficient snapshots with WORM capabilities is available behind MinIO.
The MinIO limitations document claims an “unlimited” amount of objects or buckets, but it depends on the underlying storage and network capabilities. In our tests, we were able to create millions of objects per bucket (multiple buckets can co-exist on the same file system).
MinIO supports multi-user access control to buckets. These users can be defined on the server, can be stored in etcd, or sourced from the corporate Active Directory/LDAP environment.
In this simple setup, the MinIO gateway is completely stateless. For the test and dev environments, where high availability is not critical, such a simple solution might be satisfactory. But what about use cases when higher throughput is required, or where downtime is not an option?
In this case, several MinIO gateway servers can be deployed, pointing to the same NAS file system. DNS round-robin can be used for simple load distribution, while Nginx or HAproxy can be deployed for a setup that may require higher availability. Note that in all cases the InfiniBox implements a high availability backend, with a 100% data availability guarantee available.
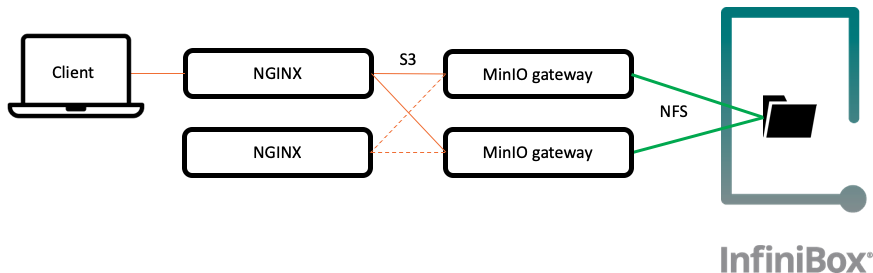
Fig. 3 - Highly available MinIO environment behind NGINX load balancers
NGINX can balance incoming traffic and spread it evenly across multiple Minio server instances. There are several online documents (1, 2) describing how to set up NGINX in front of MinIO.
NGNIX servers can also be configured in HA mode. In this scenario, a second NGINX server must be installed. Keepalived can be used to ensure the highest availability.
It is also possible to run MinIO within a Kubernetes cluster. This setup allows easy scale-out and scale-back of the number of gateway nodes based on the workload. The Kubernetes Service offers load balancer functionality, and the Infinidat persistent storage provisioner can be configured to automatically provision the required storage capacity.
Where could such setup be used?
It could be used as a target for backup applications, as a Splunk Smartstore implementation, an HDFS replacement in a Hadoop environment, or in many other use cases which require object storage functionality.
Object storage can also be used as a data lake, storing large amounts of structured and semi-structured data. This is an especially common scenario for customers running in the public cloud. Amazon announced the S3 SELECT API during AWS re:Invent 2017 to better support this use case. MinIO implements this API, which is not commonly available with other on-premises object storage solutions. It is designed to pull out only the required data from an object, and can dramatically improve performance and reduce the cost of applications that need to access data in S3.
Let’s assume we store multiple CSV, JSON or Parquet files in an S3 bucket. It’s certainly possible to retrieve the entire table or a set of tables and process them on the client-side. But S3 SELECT helps to limit the retrievable part of the table only to the required content, reducing network bandwidth requirements, especially for large datasets. Here is a Python code snippet with a sample S3 SELECT query:
s3 = boto3.client('s3',
endpoint_url='http://miniogw:9000',
aws_access_key_id='minio',
aws_secret_access_key='minio123',
region_name='us-east-1')
r = s3.select_object_content(
Bucket='ibox-bucket',
Key='TotalPopulation.csv.gz',
ExpressionType='SQL',
Expression="select * from s3object s where s.Location like '%Israel%'",
InputSerialization={
'CSV': {
"FileHeaderInfo": "USE",
},
'CompressionType': 'GZIP',
},
OutputSerialization={'CSV': {}},
)More details about S3 SELECT can be found on the MinIO or AWS sites.
MinIO is a very popular S3 implementation, and it provides a simple, quick-to-deploy object storage solution. Deploying it in front of the InfiniBox allows customers to benefit from our reliable, high-performance storage solution with enterprise-class functionality at scale and avoid deployment of multiple, incompatible storage solutions.
